VLMOD
Understanding Multi-Object World from Monocular View
- Language and binocular vision play a crucial role in human understanding of the world. Advancements in artificial intelligence have also made it possible for machines to develop 3D perception capabilities essential for high-level scene understanding.
- However, only monocular cameras are often available in practice due to cost and space constraints. Enabling machines to achieve accurate 3D understanding from a monocular view is practical but presents significant challenges. We introduce MonoMulti-3DVG, a novel task aimed at achieving multi-object 3D Visual Grounding (3DVG) based on monocular RGB images, allowing machines to better understand and interact with the 3D world.
- Our code are available at https://github.com/astudyber/MonoMulti-3DVG
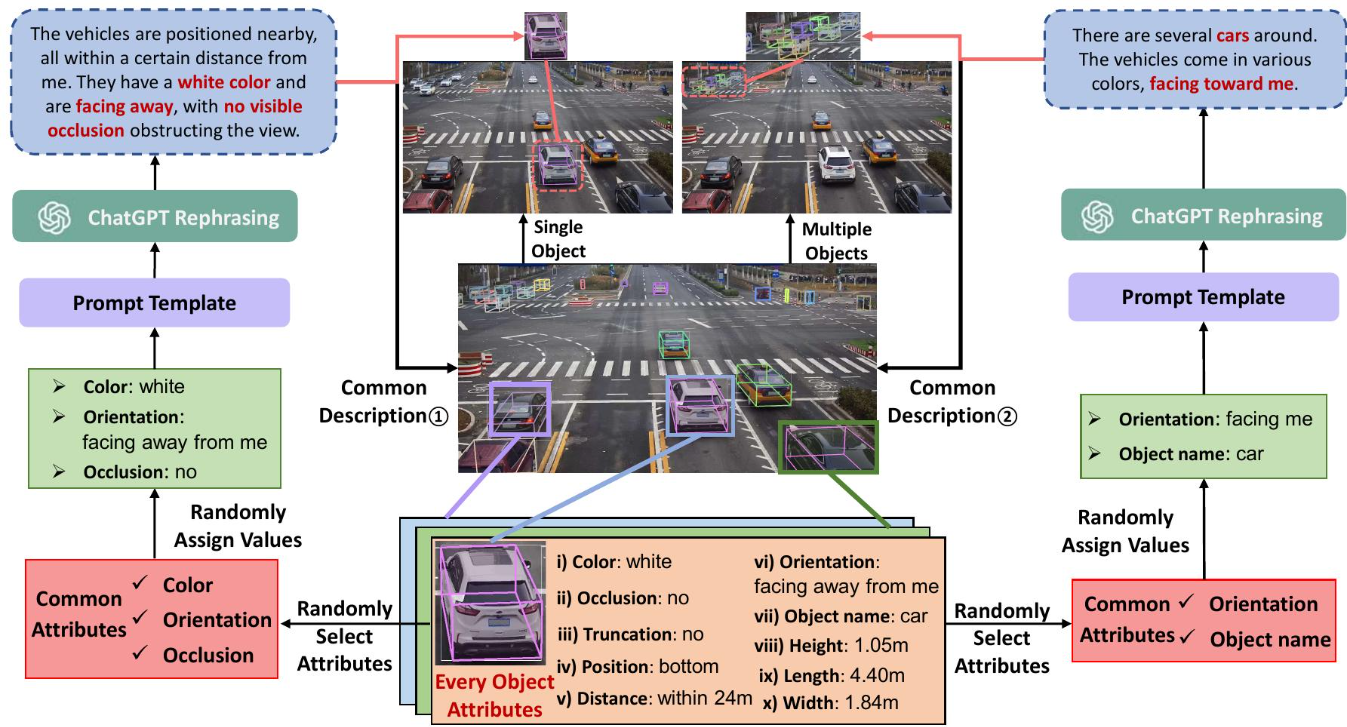
Submission Guidelines
MonoMulti3D-ROPE Dataset: By applying, you can obtain the download link for the annotation file corresponding to the dataset. To avoid infringement, please obtain the images corresponding to the dataset from the Rope3D dataset: "Rope3D: The Roadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task". You can also download it through the following link: https://drive.google.com/file/d/19JYRbHMxuqRr95LTSEynSYPmvsxwLmLE/view?usp=sharing
In the test set, you will receive a series of JSON files corresponding to the image names.
- 'public_description' consists of three textual descriptions
- 'test_data' is a 3D coordinate corresponding to N current images
What you need to do now is to generate a txt truth file with the same name for each JSON test file
- Example input JSON:
{ "public_description": ["text A","text B","text C"], "test_data": ["car 0 1 1.801794718014159 432.329712 161.031845 489.911163 195.766006 1.330764 1.723862 4.595827 -23.599788856 -17.3461417017 107.76086501 1.58619703569 white", "car 0 0 1.8714389585917863 271.055511 260.568756 369.843994 326.276459 1.226748 1.293225 4.509353 -17.0402855068 -6.51409203148 60.3178077787 1.59610576362 black", "car 0 0 1.9176106259634207 152.466553 233.118301 249.770584 294.002746 1.368777 1.354342 4.576945 -23.1791681767 -8.31255693637 68.7484072947 1.5924206198 white", "car 0 0 4.548582196278255 1380.783569 357.924286 1497.573242 443.193329 1.000533 1.625677 4.351937 10.2291397219 -2.78002294124 45.1663406086 4.77130207357 red"] } - Example output txt:
0 0 0 0 0 0 0 0 0 0 1 1
The first line 0 0 0 represents that the coordinates of the first car in the "test_data" array do not match any of the three text descriptions. Similarly, the last line 0 1 1 represents that the coordinate information of the fourth vehicle matches the description information of text B and text C.
The submitted forecast results should be organized according to the following structure:
├── 1632_fa2sd4a11North151_420_1613716796_1613719782_123_obstacle.txt
├── 1632_fa2sd4a11North151_420_1613716796_1613719782_162_obstacle.txt
├── ...
└── ...
Finally, submit a zip file containing the predicted values of all test samples in txt format. Please strictly follow the above format for submission. After submission, wait a few minutes for the system to rate.
Method Leaderboard
| Method | F1 Higher is better | Precision Higher is better | Recall Higher is better | TP Higher is better | FP Lower is better | FN Lower is better |
|---|---|---|---|---|---|---|
|
Last submission: 2025-11-24
|
72.9435 | 64.4322 | 84.0457 | 2576 | 1422 | 489 |
|
Last submission: 2025-08-06
|
69.0900 | 54.4600 | 94.4700 | 63139 | 52806 | 3698 |
| Guo, Keyu, Huang, Yongle, Sun, Shijie, Song, Xiangyu, Feng, Mingtao, Liu, Zedong, Song, Huansheng, Wang, Tiantian, Li, Jianxin, Akhtar, Naveed, others, Beyond Human Perception: Understanding Multi-Object World from Monocular View. In Proceedings of the Computer Vision and Pattern Recognition Conference, 2025. | ||||||
|
Last submission: 2025-11-24
|
68.0373 | 66.0221 | 70.1794 | 2151 | 1107 | 914 |
|
Last submission: 2025-11-24
|
67.3867 | 63.1234 | 72.2675 | 2215 | 1294 | 850 |
|
prs
Open Source
Last submission: 2025-11-24
|
65.7488 | 54.2809 | 83.3605 | 2555 | 2152 | 510 |
|
Last submission: 2025-11-24
|
64.8824 | 52.4557 | 85.0245 | 2606 | 2362 | 459 |
|
Last submission: 2025-11-24
|
64.4080 | 50.6639 | 88.3850 | 2709 | 2638 | 356 |
|
Last submission: 2025-08-31
|
63.7000 | 49.8200 | 88.3000 | 55954 | 56364 | 7416 |
| Zhang, Yiming, Gong, ZeMing, Chang, Angel X, Multi3drefer: Grounding text description to multiple 3d objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023. | ||||||
|
Last submission: 2025-08-31
|
63.4100 | 49.7700 | 87.3600 | 55657 | 56172 | 8051 |
| Cai, Daigang, Zhao, Lichen, Zhang, Jing, Sheng, Lu, Xu, Dong, 3djcg: A unified framework for joint dense captioning and visual grounding on 3d point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022. | ||||||
|
Last submission: 2025-08-31
|
61.7100 | 48.7100 | 84.1700 | 56232 | 59221 | 10573 |
| Zhao, Lichen, Cai, Daigang, Sheng, Lu, Xu, Dong, 3dvg-transformer: Relation modeling for visual grounding on point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021. | ||||||
|
Last submission: 2025-08-31
|
58.6800 | 45.3000 | 83.2700 | 50397 | 60854 | 10122 |
| Yuan, Zhihao, Yan, Xu, Liao, Yinghong, Zhang, Ruimao, Wang, Sheng, Li, Zhen, Cui, Shuguang, Instancerefer: Cooperative holistic understanding for visual grounding on point clouds through instance multi-level contextual referring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021. | ||||||
|
Last submission: 2025-08-31
|
58.0100 | 44.7500 | 82.4100 | 49883 | 61579 | 10647 |
| Achlioptas, Panos, Abdelreheem, Ahmed, Xia, Fei, Elhoseiny, Mohamed, Guibas, Leonidas, Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In European conference on computer vision, 2020. | ||||||
|
Last submission: 2025-08-30
|
56.6700 | 44.1900 | 78.9800 | 48411 | 61140 | 12884 |
| Chen, Dave Zhenyu, Chang, Angel X, Nie{\ss}ner, Matthias, Scanrefer: 3d object localization in rgb-d scans using natural language. In European conference on computer vision, 2020. | ||||||
|
Last submission: 2025-11-23
|
53.1220 | 36.3060 | 98.9560 | 3033 | 5321 | 32 |
|
Last submission: 2025-11-24
|
38.9825 | 24.2101 | 100.0000 | 3065 | 9595 | 0 |
|
Last submission: 2025-11-15
|
35.9155 | 22.3684 | 91.0714 | 51 | 177 | 5 |
|
Last submission: 2025-11-22
|
35.9140 | 31.7275 | 41.3734 | 20172 | 43407 | 28584 |
|
Last submission: 2025-11-23
|
35.9140 | 31.7275 | 41.3734 | 20172 | 43407 | 28584 |
|
Last submission: 2025-11-21
|
29.2857 | 19.4313 | 59.4203 | 41 | 170 | 28 |
|
Last submission: 2025-11-23
|
19.4030 | 20.9677 | 18.0556 | 13 | 49 | 59 |
|
Last submission: 2025-12-31
|
- | - | - | - | - | - |